
Part I
This post if about the advantages and pitfalls and getting Wilson’s algorithm to get to work for ranking content on a content producing website. Spigit is a collaborative innovation platform in which people can a post ideas in response to a challenge and people can vote up/down on the ideas. Sometimes it is also possible to star rate an idea. Naturally ranking ideas is a BIG and important part of the Spigit algorithms initiative.
Evan Miller has a fantastic post on “How not to sort by average rating” . In it he explains how Wilson’s algorithm can be effectively used to rank content (like ideas) when the vote is not complete i.e. idea A gets 10 up votes and 5 down votes whereas idea B gets 100 up votes and 50 down votes. Which idea should be ranked higher? Wilson’s algorithm works much better than averaging or aggregating in some other way. An incomplete vote means that none of the ideas get an equal amount of votes and are therefore cannot be directly compared. For example, an idea with 150 votes has seen much more criticism than an idea with say 15 votes and therefore the confidence in the ranking of the former idea must be higher than the later.
This can occur because of multiple reasons. One of the reasons is just appearing before any other idea so that voters see that idea first and therefore the idea keeps on getting more votes due to the sheer happenstance that it arrived first. This phenomenon is often termed as rich-get-richer phenomenon. Duncan Watts has a brilliant book which sort of explain the reasoning behind this phenomenon. So apparently Wilson was well aware of this statistical problem when ranking items without a complete vote and figured out a solution of it in 1927. In short, the solution is to pretty much “fake” a complete vote and then compute the ranking. The faking of the vote happens from a Normal distribution within a certain confidence range. The confidence results percentages chosen result in a damping variable being added to the denominator of the equation.
Many people reddit, yelp, digg and maybe more have encountered this problem before and have solved the problem pretty well using Wilson’s ranking. Here I will try to give a brief of how Wilson’s algorithm works in plain English.
Consider an idea has following variables associated with it –
v = views received, u = up votes received, d = down vote received.
Wilson’s algorithm ![]() takes the u and d votes on an idea and comes up with a score. Now let us assume that every idea has a “real” score which we are trying to calculate. Let the real score be
takes the u and d votes on an idea and comes up with a score. Now let us assume that every idea has a “real” score which we are trying to calculate. Let the real score be 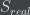

In reality it is impossible to know what the inherent real score of an idea is unless we actually implement that idea and analyze the scores based on empirical data. But we cannot do that. So we have to get as close as possible to the real score using the data we have i.e. the up and down votes crowd sourced from the users. Thus we want 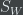


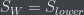
There is also another reality that we have to deal with – that all ideas are not submitted at the same time and therefore will not receive the same number of votes. Presumably the ideas which are submitted earlier will receive more votes than those which are submitted later w.r.t. the point at which the scores are computed. This creates a bias based on the time of submission. Late submitted ideas which are potentially good might not score high enough simply because they haven’t had the same amount of exposure than some of the earlier submitted relatively mediocre ideas. This is an important issue and Wilson’s algorithm addresses it. What it does is it tries to balance the fraction of positive votes received with the uncertainty of the time for the idea was exposed. Simply put, if an idea is receiving decent amount of positive votes but has not been exposed for a long time, Wilson’s algorithm will figure out how many positive votes will it receive proportionally had it been exposed for more time like some of the other ideas. This is done by introducing a damping variable generated from a Normal distribution (the 
There are 3 imp things in that sentence
1. “given the rating that I have” – These are the actual up and down votes received by an idea. So for an idea which receives very few up and down votes the range in which the real score lies is going to be large. For an idea which has a large amount of votes, the bounds will get tighter and tighter around the real score. Thus for an idea with really less votes the lower bound (which we take as the score) will be farther apart from the real score than for an idea which receives a lot of votes. Therefore it is better to have large number of votes.
2. 95% chance – This is the confidence in the computed score. The bounds computed by Wilson’s algo are affected by the confidence. Higher the confidence the bounds are very likely to be more relaxed. If you can work with lower confidence in the score the bounds are likely to be tighter. The bounds vary to compensate for the confidence needed in the computed score.
3. the “real” score – this is the score which we want to come to; “is at least what” because we use the lower bound as the score.
References
